2018 marked history as the year when governments made tech giants responsible for election interference and tumult in democracy. Centralization and decentralization were central themes in cyberspace this year, while regulation and freedom also defined the rhetoric of many actors. We understood how closely cyberspace and meatspace affect each other, demonstrated by a couple of key events in 2018.
FB and GOOG peaked

(Source: Reuters)
When the Cambridge Analytica data scandal was published on March 17th, FB stock took a big hit. In April, Zuckerberg appeared before U.S. Congress to testify, leaving answers that many felt were unsatisfactory. A few months later, as their Q2 earnings report demonstrated little to no growth, many investors immediately sold their stock, leading to 20% drop in price ($120 billion in value). Many seemed to realize that FB is not doing well, neither as a business, nor as a platform for humane discourse.
As a result, FB stock prices this year went 2 years back in time, back to prices similar to early 2017. GOOG stock prices had a similar performance, as GOOG also received some negative press related to YouTube’s role in election interference, as well as leaks that revealed a deteriorating company cohesion, lower commitment to ethics, and protestable handling of sexual harassment incidents. Other Silicon Valley companies shared similar troubles. In 2017, Uber was a source of company culture scandals, but in 2018 its business showed signs of slowing.
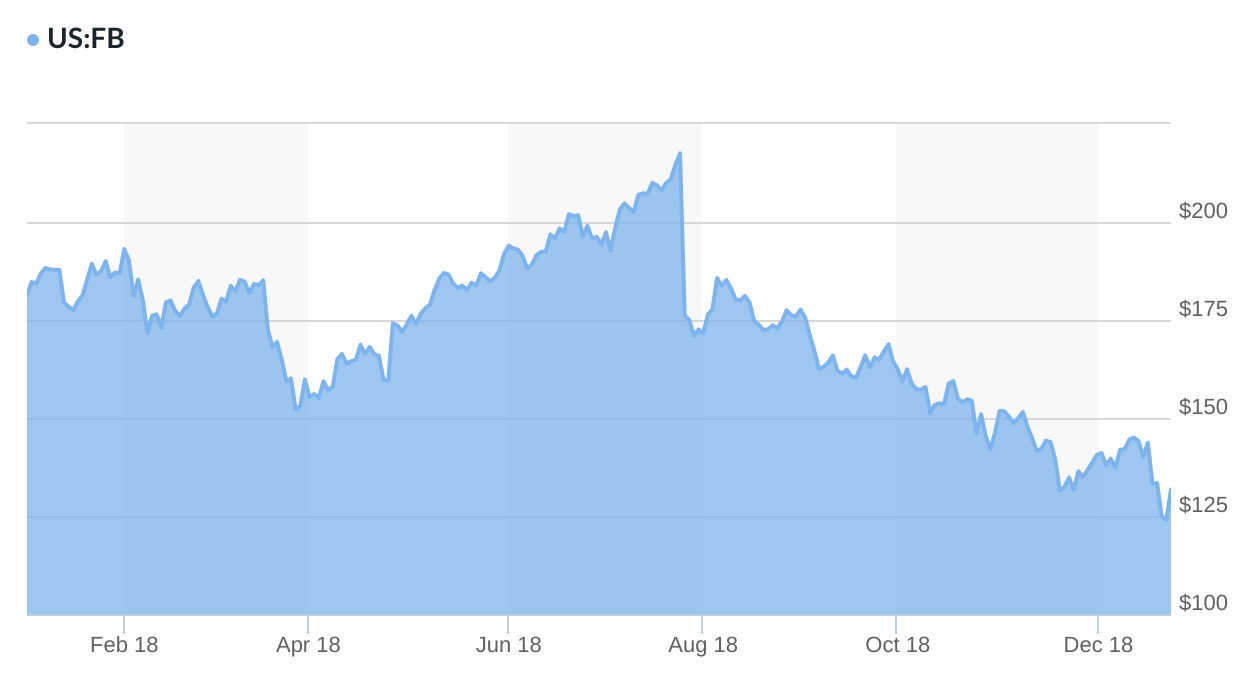
(Source: MarketWatch)
The overall sentiment from the population has shifted: in a American poll of opinion, more people believe that social media hurts democracy more than it helps. The public perception of tech giants has gotten worse. In 2017, #DeleteUber was a trending hashtag. In 2018, it was #DeleteFacebook’s turn, causing more than 40% of young adults in the U.S. to delete the app from their phones. Even the co-founder of WhatsApp (a FB subsidiary) Brian Acton used the same hashtag to express his views, after quitting his position at FB. Other directors, such as Instagram’s (another FB subsidiary) co-founders, had a more graceful exit from FB. But the consistent message coming from many former executives, presidents and investors is that FB has crossed the line, becoming psychologically harmful and destroying how society works.
The common themes for tech giants in 2018 were evaporation of reputation, and a decline in business. Their reputation got attacked internally and externally, from multiple angles and stories. This year, many discovered that these companies are darker than we thought. I am an outspoken critic of FB for years, but if you told me earlier this year that FB would hire Definers Public Affairs to lift negative stories on FB-critical senators, I would have dismissed that as an exagerated prediction. But this happened, and we’re all learning how dark these tech giants actually are, thanks to internal leaks and adversarial journalism.
On the business side, it seems like these giants have saturated their products. FB’s Facebook growth has stalled in the USA, probably because more than 70% of Americans are regular (monthly active) Facebook users. GOOG focused on maintaining its current Search and YouTube ad revenue, while attempting to grow its AI efforts and Cloud business, where it still has not guaranteed leadership. GOOG is actually lagging behind when it comes to the Cloud, and its AI products are promising but are not yet reliable revenue streams. In 2018, GOOG also continued to discontinue many of its non-key products, such as Inbox, Google+ for consumers, and Fusion Tables, which harms its credibility as a reliable provider of services, important as a Cloud business.
Less social networks

(Unknown source, please contact me if you know who the author is)
The sunsetting of Google+ for consumers is an important marker for the web in 2018, because it consolidates FB’s dominance in social networks. It’s not the first time that GOOG discontinues a large social network, Orkut was once a social network with dozens of millions of active users. Ironically, one of the reasons GOOG discontinued Orkut was the prospect of Google+ and its potential to replace Orkut.
The problem with discontinuing small platforms (yet multi-million user large!) is that it removes consumer choice when the tide changes. Orkut was very popular among Brazilians, but began losing space to Facebook in 2009. However, now that Facebook’s credibility is decreasing, users have no choice of going back to a previous social network. This lack of platform competition is due to such platforms being proprietary.
It is easy for one company to acquire and assimilate another social network. Companies do that because by joining platforms together they acquire more power and efficiency. It is also easier for companies to discontinue a platform, and they do that when the costs of running the platform don’t justify the small gains. Therefore, among proprietary for-profit social platforms, only the large and merged platforms tend to survive. Hence, Facebook. However, had the platform been a non-commercial open protocol (such as the Web or Email), its availability would be much more reliable and independent from any company’s seasonal performance, likely surviving for many decades.
Another 2018 story on social networks was the content crackdown that Tumblr imposed on adult content, including artistic communities, that forced many users away from its platform. For many users it spelled the end of that social network. As a proprietary platform, Tumblr was first acquired by Yahoo, which in turn was acquired by Verizon in 2017. This means Tumblr is subject to the same instability and uncertainty that is inherent of a platform hanging on the decisions of a few business executives legally entitled to steer the platform.
Regulation
In the European Union, 2018 was the year when GDPR was switched on, requiring deep changes to a huge proportion of sites and internet services run by organizations around the world. For many sites targeting national (e.g. American) audiences, such as Chicago Tribune, GDPR compliance was not worth it, so these sites became unavailable to European readers. While GDPR may have sparsely helped in its original goal to increase user control over personal data, it had a role in furthering the balkanization of the internet, already norm in China.
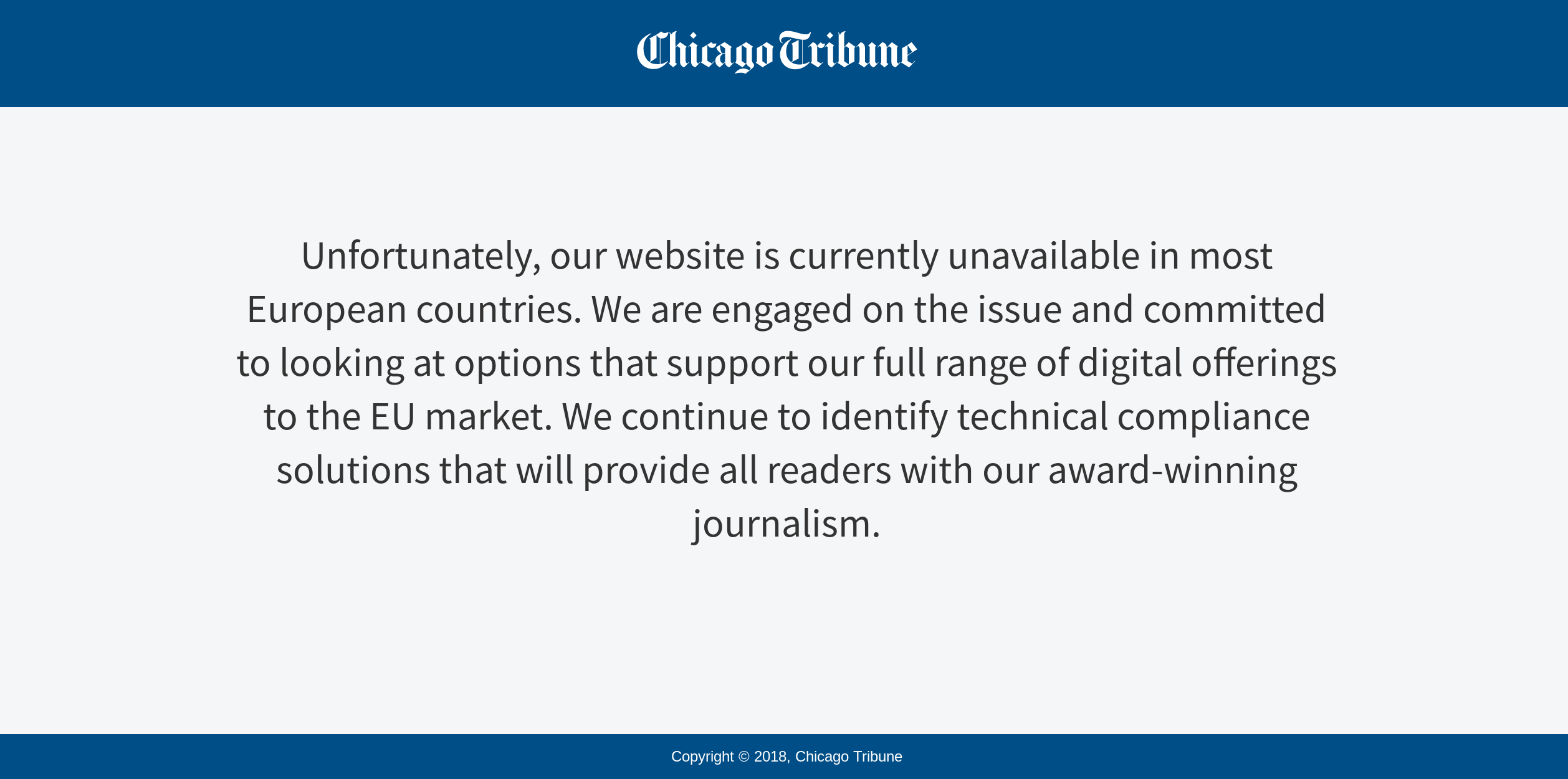
(Source: Chicago Tribune)
The EU is aiming a lot of new regulation at tech giants and the internet at large. GDPR was not the only one, as Europeans are already familiar with the infamous cookie banner for years. While most of regulation is intended to limit corporate exploitation and protect user freedom, some new proposals, such as the Link Tax and Upload Filters may significantly harm openness and freedom on the internet. In September 2018, unfortunately, the EU Parliament decided to proceed with the proposal.
Like GDPR triggered suddenly for many unprepared organizations, so may new legislation continue to add obstacles to internet traffic and rich information exchange globally. Many of these organizations may not find it cost-beneficial to serve European users anymore.
NY-FB cyberwar
In 2018 the press and FB became enemies. Last year I blogged about how the Web began dying in 2014 and it has to do with traffic sources to news sites. In the recent years, the online press became more dependent on FB and GOOG for the vast majority of their traffic, putting professional journalism at the mercy of these giant platforms. Moreover, large news sites often were in competition with lower-tier sensationalist fabricated articles spreading quickly on platforms like Facebook. Naturally, the press got upset.
The New York Times this year had a storm of articles published specifically on FB scandals, too many for me to quote ([1] [2] [3] etc). Similar in tone, the New Yorker also had incisive stories to report.
In Menlo Park, CA, Zuckerberg started the year by pledging to “fix Facebook”. Months later, after the turbulence caused by the Guardian’s and NYT’s articles about Cambridge Analytica, Zuckerberg adopted a war attitude internally at FB.
The tense exchange between FB and NY press is logical, they are competing in the same market: attention and advertisement. And while FB denies that it is a publisher, what matters is that both FB and the press monetize eyeballs, and their competition for attention is a zero-sum game.
AMZN / MSFT / AAPL soared
Meanwhile, the other tech giants had an easier year, not occupying the negative spotlights in the press, not having to answer frustrated senators in Congress, and increasing their market capitalization. While FB and GOOG finished the year with -29% and -7% (respectively) stock value compared to the beginning of the year, AMZN and MSFT stock prices went up 17% and 14% (respectively). Jeff Bezos became the richest person on Earth in July. AAPL became the world’s first trillion dollar company, marking history. Soon after, though, AAPL’s value declined and MSFT was able to pass it and acquire the title of most valuable U.S. company.
Because these tech giants are not competing in advertisement and are not surveillance capitalism companies, they had a much easier year in terms of publicity. While none of these companies are paragons of user freedom and privacy, people tend to place the blame mostly on FB and GOOG for psychological damage in social media addiction, misinformation, and political social engineering.
Blockchain winter
Cryptocurrencies peaked in value a few weeks before 2018 began, and after 12 months, all of the top cryptocurrencies saw a 70%+ drop in value. You could easily say the Bitcoin bubble burst, as many were already expecting in 2017.
ICOs in 2018 raised 3 times more money than in 2017, but 2018 was not a great year for ICOs. Many people noticed a large amount of scam ICOs, and in the U.S.A. the government began the process of regulating ICOs and often classifying them as securities. The number of ICOs has been steadily declining since mid 2018. Overall, 2018 was a difficult year for cryptocurrencies, but there are plenty of respectable active projects to compensate for the scams, and even though cryptocurrencies entered the mainstream and casual discourse, we are still talking about an industry in its infancy.
Cryptocurrencies will become center of attention again when the global stock market enters a recession and people look for alternative stores of value. At the very end of 2018, we may be already seeing this occuring, as stocks in America have entered a bear market around December 21st, and simultaneously major cryptocurrencies like Bitcoin and Ethereum have risen noticeably.
Peer-to-peer grassroots
When the topic is decentralized technologies, cryptocurrencies usually take the spotlight, but one ramification of decentralization are the non-blockchain peer-to-peer (P2P) projects, also known as the “Decentralized Web” (DWeb), such as IPFS, Dat, SSB, ZeroNet, Holochain, Solid, WebTorrent, Matrix, SAFE, GUN, Althea, etc. These have had a great year, although they are small in scale. One could say these P2P projects were behaving in 2018 like cryptocurrencies were in 2015-2016: not occupying mainstream discourse, but still promising, in active use, diverse, and thriving.
The highlight of this movement was the Decentralized Web Summit that took place in San Francisco in August. Young pioneers and industry veterans were equally excited about the tangible innovation and opportunities ahead. Vint Cerf, inventor of the TCP/IP protocol, called it a historical summit. Tim-Berners Lee, creator of the WWW, was also present.
On January 5th this year, as fellow developer André Garzia was working on Firefox extension for SSB called Patchfox, he wanted to add support for the ssb:// protocol in addresses, and sent a commit to Firefox to permit a few more decentralized protocols. I call this the DWeb big bang commit, it was a small effort but brought these protocols to public attention, as the commit ended up in the Firefox Update changelog, also leading to articles reporting about the change.
Months later, Mozilla Hack’s blog featured a series of articles on DWeb protocols, Mozilla gave an open source grant to the Dat project, and began the libdweb experiment as a set of new browser capabilities useful for DWeb protocols, enabling TCP servers in the browser and even full IPFS nodes in the browser. Other browsers started catching up with Firefox: Chromium began discussion to permit new decentralized protocols following Firefox’s example. There is now a website where you can check how well do major browsers support the DWeb: arewedistributedyet.com. I have to say, in January I predicted this would happen.
That said, the one browser that took the DWeb spotlight was undoubtedly Beaker Browser, which this year had a redesign, several conference talks, and a thriving community of creators, which is indicative of a successful project. Beaker’s success so far has been making authoring and publishing a first-class experience of the web, not as data submitted to a server, but as actual HTML sites authored from scratch. It’s a love letter to the web’s original design: “the creation of new links and new material by readers, [so that] authorship becomes universal”.
On the social side of the web, Secure Scuttlebutt (SSB)’s community grew to over 10k accounts and 100k connections, Manyverse was launched as the first SSB mobile app (by yours truly), and the wider community received significant funding from Handshake.
In other projects, significant advancements happened in 2018 like OSCoin’s release of Radicle, and the rise of Holochain. There’s too many news to fit in this article, but the bottom line is that decentralized web projects are now beyond experiments, they are working hard towards maturity and beginning to develop end-user apps.
These projects have also appeared on the radar of tech companies, also literally, as ThoughtWorks marked IPFS as an ‘assess’ item in its tech radar. IPFS also took headlines when Cloudfare decided to setup a IPFS gateway, providing a web-accessible endpoint to content hosted throughout IPFS nodes. Another company aware of the DWeb is Samsung, which announced this year the Samsung NEXT Stack Zero Grant specifically to the peer-to-peer web and decentralized projects. The DWeb also got mentioned in higher ranks, when Rep. David Cicilline was questioning Google CEO Sundar Pichai in Congress and said “Along with 83% of americans, I strongly support an open decentralized internet that is free of powerful gatekeepers”, echoing Tim-Berners Lee’s articles on re-decentralizing the web.
2019?
To the best of my estimates, I can give some predictions for 2019 or early 2020.
There will be a global economical recession. We are certainly in the latter stages of an optimistic period, and with political instability, US-China trade wars, and tech giant underperformance, the economy is fragile for any event that will tip it towards pessimism. This will affect tech giants directly, because they are all publicly traded companies, and one could say we’re already seeing the beginnings of recession since October 2018.
FB will devaluate steadily throughout 2019. It might spike up in reaction to some good decisions, but the tendency will be downwards, because the overall economy will be difficult, and because of FB’s own issues. The sentiment around Facebook.com will also continue to decay, but keep an eye on Instagram and WhatsApp. Even if all Facebook.com users join the #DeleteFacebook movement, they are much less likely to delete their WhatsApp and Instagram apps, and many don’t even know that FB owns all these products. FB knows this, and they will defend the business and user experience in those apps. Supposing Facebook.com dies (I don’t think it will), WhatsApp and Instagram can be FB’s second chance of getting it right. Maybe Zuckerberg apologized for Facebook so much because that is where all the mistakes were committed, maybe their next platforms will be better. There are talks that FB should be broken apart, one company for each of these products, but FB will do everything (also lobbying) to avoid a breakup of their social monopoly.
Overall, although FB constantly occupies scandalous news headlines, we are underestimating FB. No other platform has made 90%+ of (non-China) internet users their monthly active users (2.6 billion users of FB products, divided by 3.5 billion non-China internet users), which means if any two random persons want to be in contact over the internet, the easiest way is very likely to be through FB products. That is of immense value and does not die out quickly, and it is hard to compare the hypothetical sudden death of Facebook to other sudden deaths of other internet platforms, because literally no other internet platform has yet been as large as Facebook. I myself am blocking both GOOG and FB services from my computer for 2+ years, and I recognize that it is vastly easier to stop using GOOG services than it is to be outside FB products. I am constantly reminded that I am excluded from a lot of social activities, and I know that my choice also causes an uncomfortable social burden on others. My search engine choice does not cause that same effect.
New York’s press war with FB has most likely caused people to be aware of the ethic underperformance of FB executives, but this is not much different to discovering that your country’s politicians and leaders are corrupt. It’s enraging, it’s protestable, and maybe if you try hard enough with enough mass coordination you can make a change, but it’s still a centralized authority so much more powerful than you are, that it leaves you feeling powerless to make a difference or even change your habits. This is just one more symptom that FB is a Net State: it has a huge population (userbase), citizen identity (login/account), constitution (content moderation rules), government (Zuckerberg and FB company), and now even other states (US government, EU, UK parliament, etc) are engaging with it and some of its citizens are protesting against it. FB as a Net State is also actively developing its Police capabilities, largely in reaction to the election interference scandals. However, this is not exclusively because of election interference, it would anyway be an inevitable next step for a Net State. See Zuckerberg’s post “A Blueprint for Content Governance and Enforcement”. Let me highlight one word in that title to make it very obvious: Enforcement.
However, FB is also underestimating us. More than any other organization, FB understands memetics, a field of study on the human drive to imitate others and the viral spread of information and behavior. I remember watching Zuckerberg testify to Congress and being asked about the #DeleteFacebook movement, where he answered that it didn’t have a significant impact on the numbers. I knew at that moment that he was lying or purposefully underplaying that effect. Everything FB does, from press releases, to designing UIs and copying competitors is about memetic engineering. They know that no one really can stop a viral movement once it is fully unleashed, and they fear that the same mechanics that unlocked their exponential growth would cause their exponential evaporation. They fear not any single entity, they fear the power of many.
GOOG in 2019 will get increasingly more boring, maintaining the basic leader position in Search, YouTube, Android, and Docs. They will keep on pushing for AI strongly, since that’s their core mission, but it’s unclear whether we will see significant AI breakthroughs in 2019 and 2020. Maybe something interesting, but not on the same revolutionary scale as iPhone in 2007. Not yet. They might also keep their tradition of discontinuing products, we might see one or two more discontinued GOOG products in 2019. Their cloud business is at risk of being (gradually) discontinued, unless perhaps by specializing in AI as a service.
Keep an eye on AMZN, AAPL, MSFT, particularly if they can build strong AI competence. While GOOG and FB still take most of the top AI talent, they also receive a lot of negative press and their employees may be on the verge of quitting, while AI is a long-term battle. With immense budget, AMZN, AAPL, and MSFT are actually good incubators for AI technology.
Cryptocurrencies will have a good 2019. Most likely not an exponential kind of growth, maybe just linear or super-linear growth. While many have considered cryptocurrencies defeated after the bubble burst in late 2017, cryptocurrencies behave financially very differently than startups, growth companies, or commodities. These are open source and permissionless databases, which mean they don’t die easily. Growth companies have budget runways, commodities are subject to specific kinds of supply and demand. But open source and open data do not die, not until everyone has lost interest. Cryptocurrencies most likely have many winters, and experience the hype cycle multiple times, each plateau of productivity blending quickly with the next peak of inflated expectations.
Regulation of both tech giants and cryptocurrencies will tighten in 2019. Governments have barely woken up to the power these two cyberforces have on real society, and since they take months and years to reactively regulate, 2019 will show regulation meant for a world from 2016, both from the EU and the USA. A first step might be the USA copying parts of EU’s GDPR.
Regarding DWeb projects, in 2019 a few (maybe one or two) larger organizations may make experimental use of decentralized protocols such as IPFS, Holochain, SSB, Dat. These might be in absolute numbers small advancements, but still significant to scale up these projects by one order of magnitude, which is considerably bigger, but tech giants are still 4 orders of magnitude bigger. Funding will be a challenge for these projects, and maybe in 2019 a few such projects might lose momentum due to lack of resources. Another challenge will be the UX Gap.
Currently, internet users are served top-notch user experience from centralized services, but are dissatisfied with the governance underperformance and freedom problems of such services. DWeb projects are technically mature to solve the governance issues, but cannot provide an easy-to-switch user experience on par with centralized services. For further funding, DWeb projects also require an app with great UX to showcase the power of the technical foundation. They will need, essentially, a Mastodon Effect. The success of Mastodon is primarily a UX success, it fits users’ expectations, looks aestetically pleasing, and just works, but the protocol foundation is somewhat lacking compared to modern P2P protocols, particularly in distributing power and authority.
More conferences will happen on the topic of DWeb, not just the Decentralized Web Summit, which means the community around these projects will grow. In 2019 we might see one, two, or three very interesting end-user apps that fill the UX Gap and are able to start thriving communities. I am excited to be part of this future, and I hope it becomes a movement larger than any individual involved. I wish you a good start for 2019, too!
]]>