EU's Copyright Directive and the P2P Internet
As an European citizen, I'm very disappointed by the way the new Copyright Directive is developing. For context, read Stratechery's analysis, which I agree with, alongside Julia Reda's blog which is abundant on this matter. I'm not an expert in Copyright, regulation, the European Union, my focus is on developing and fostering peer-to-peer protocols and open source. But the number of people who live in the intersection of all these topics is pretty shallow, even more if you consider those that want to write about this topic, so here are my two cents.
The new Copyright Directive is probably going to harm the internet as we know it, a lot, specially for europeans. But it might end up accidentally helping new peer-to-peer web protocols florish. It might end up making the current internet status quo unbearable, creating a gap that can only be filled by modern peer-to-peer protocols.
Regulators in the EU seem to have good and naive intentions of limiting the power of tech giants. These are American companies, so if they were to be broken up, it would have to be under American law, like happened with other monopolies in the past: Standard Oil in 1911, and AT&T in 1984. Americans haven't yet managed to break up the duopoly of user-generated content on the internet, and the Europeans seem a bit further on their dissatisfaction with these monopolies, so apparently they've decided to give these companies a hard time. First, with GDPR, now with the Copyright Directive.
The problem with technology regulations is that they are written with an incomplete understanding of the topic, and stipulate sometimes impossible-to-comply demands. But the end result is that usually the big companies are able to do their homework and find holes in the regulation, or dedicate teams that build features to support those demands perfectly. This process is better explained through some diagrams I drew some time ago but now finally would be convenient to share:
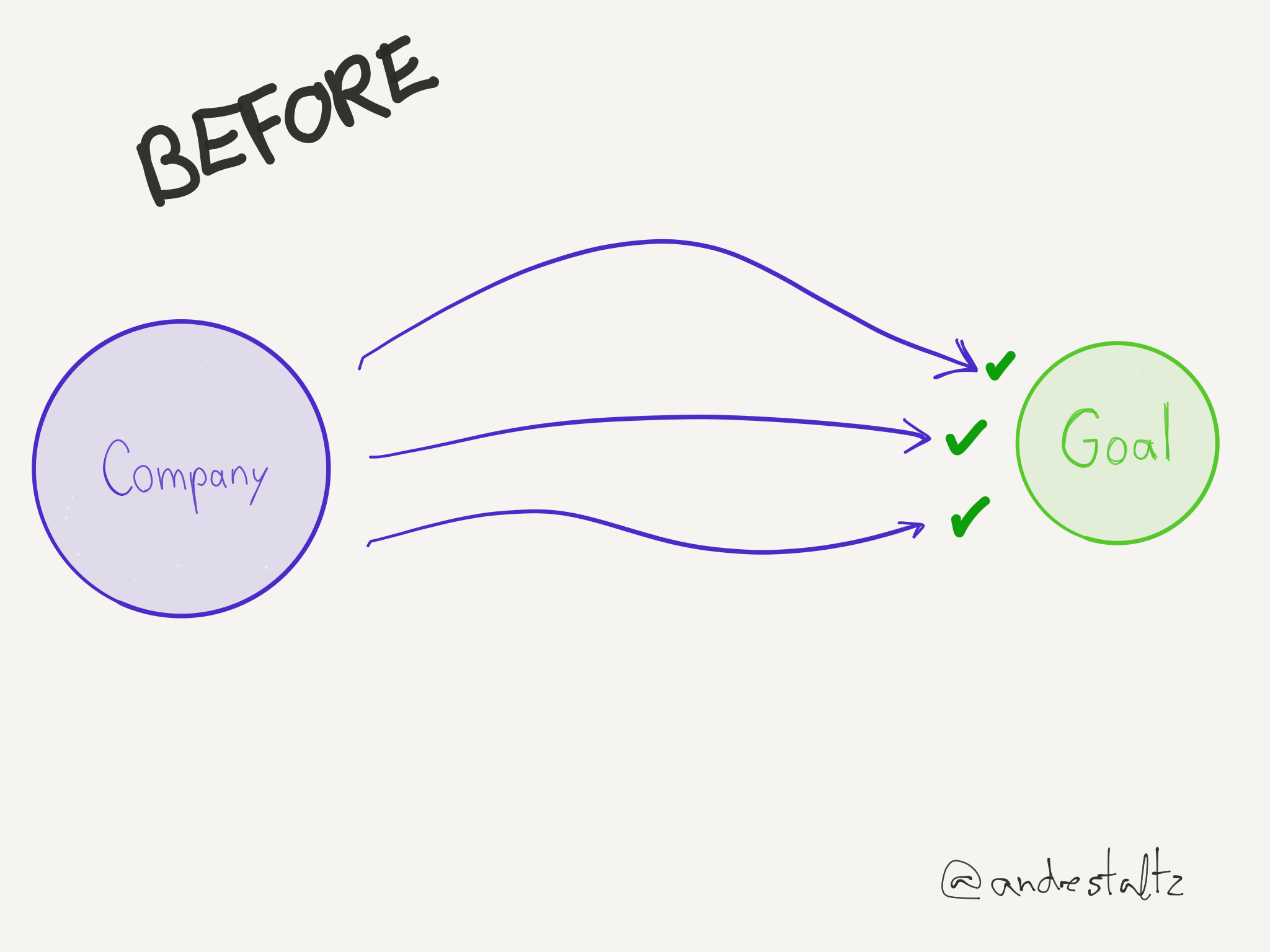
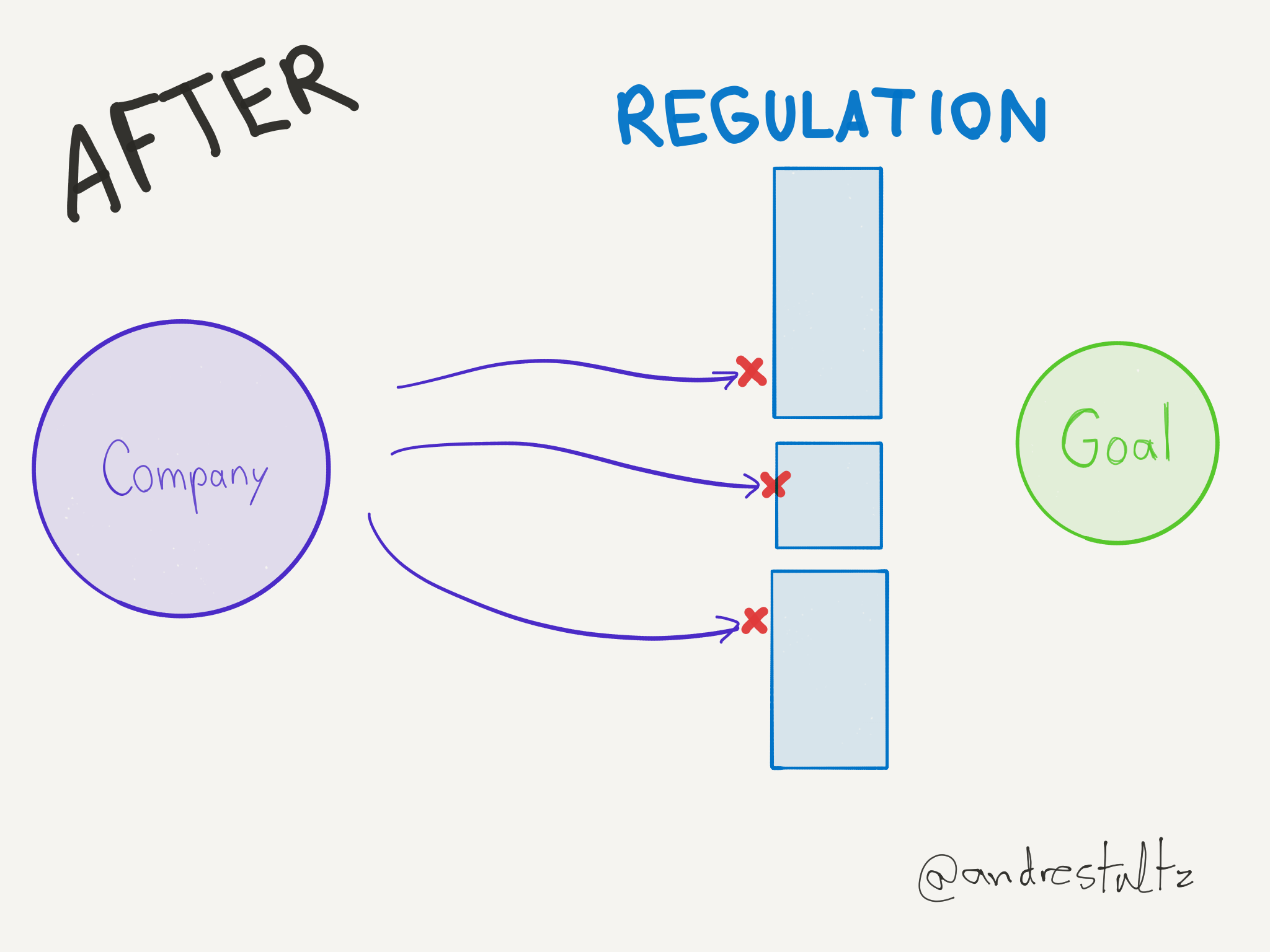
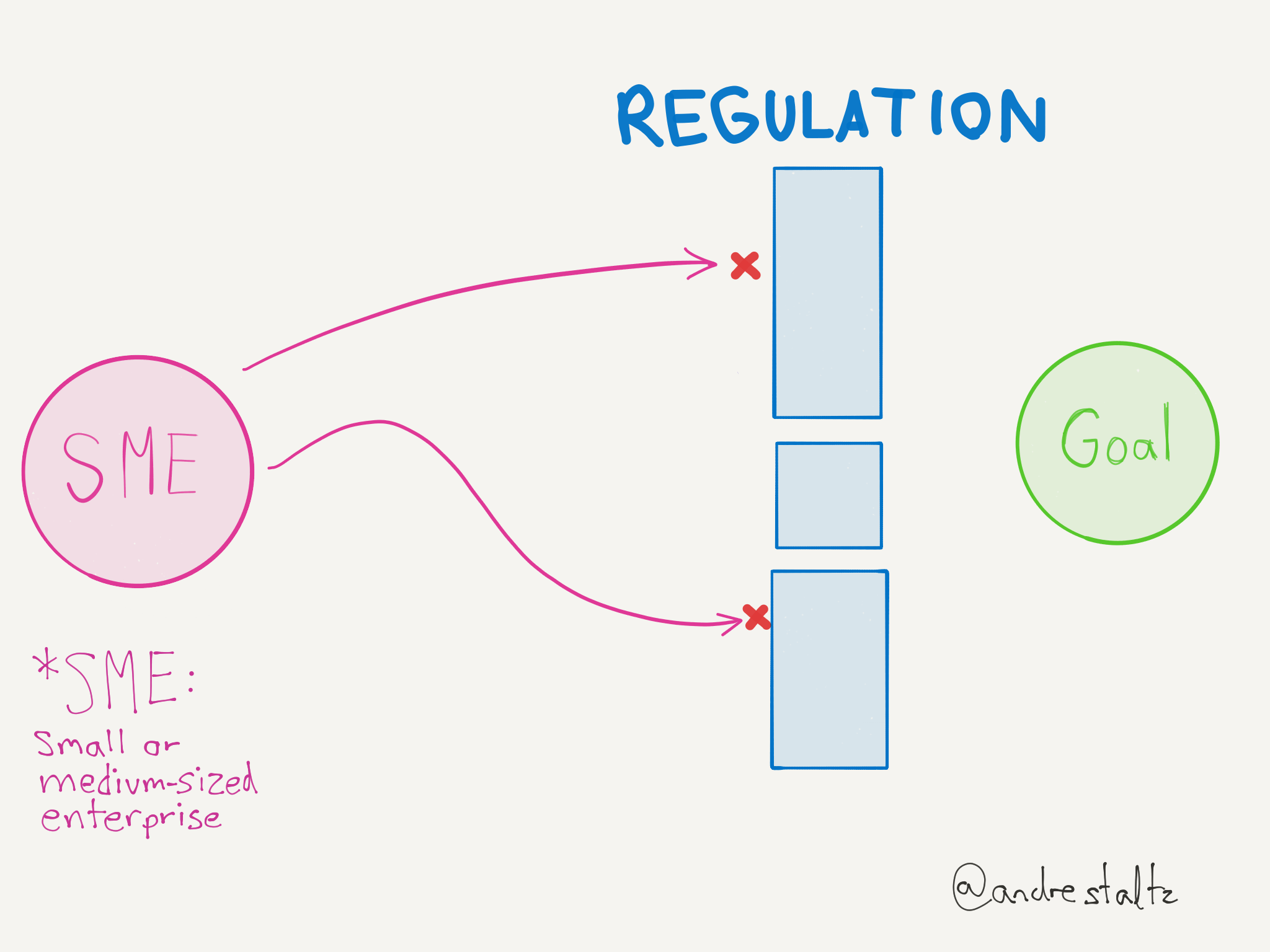
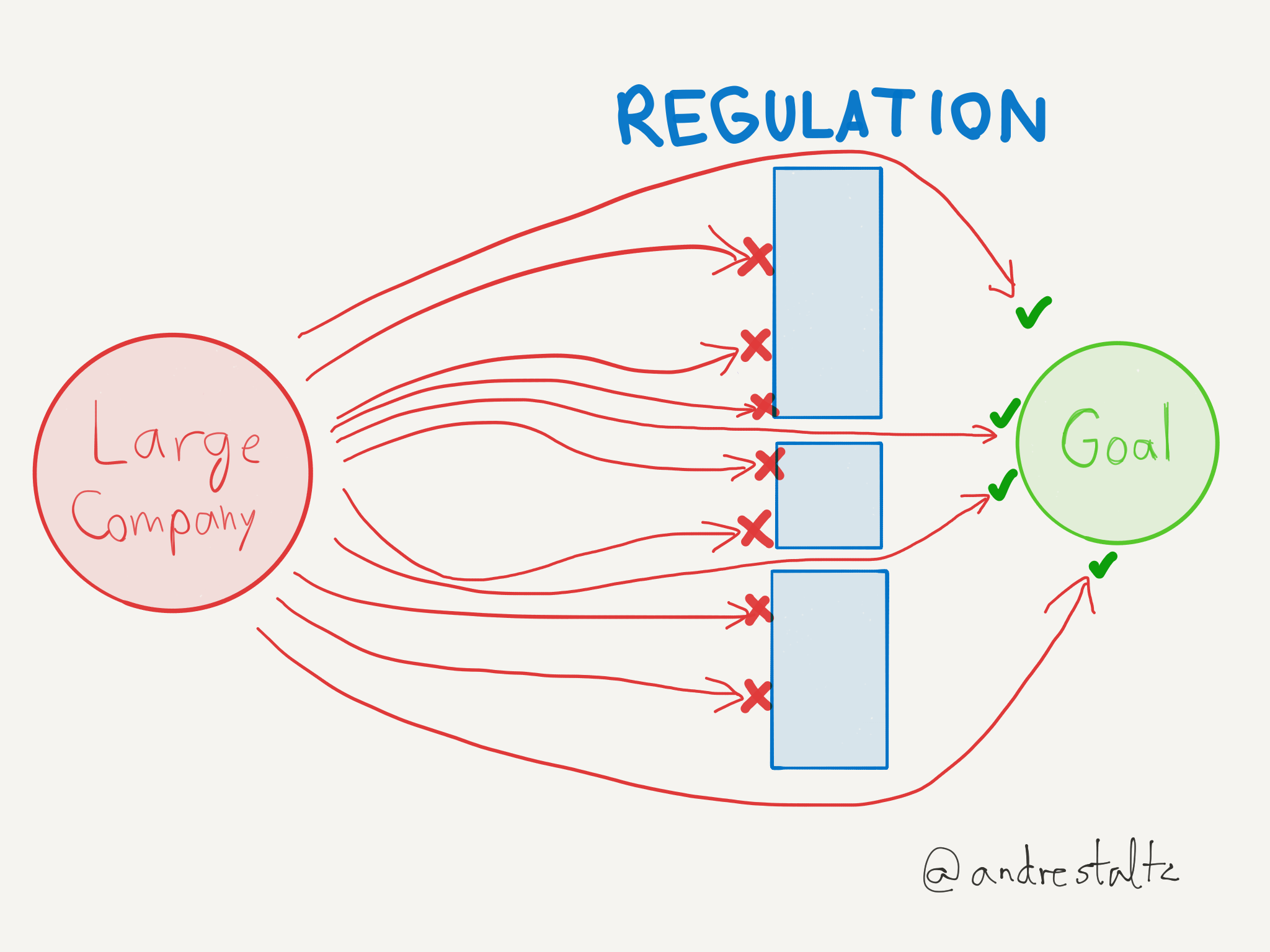
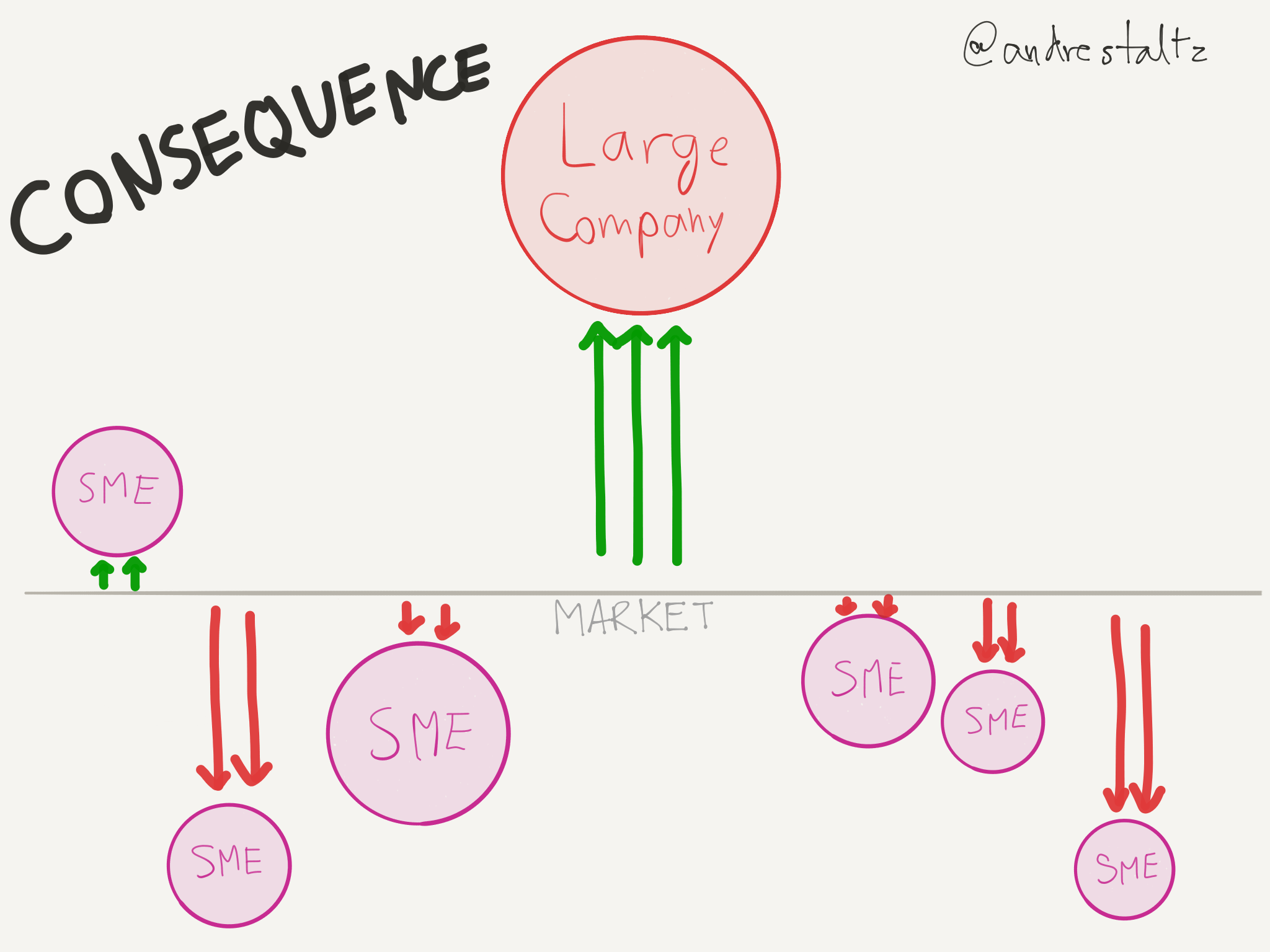
Regarding the Copyright Directive specifically, what consequences are we expecting to see?
- Tech giants will double down on machine learning for upload filters
- Smaller platforms will imperfectly comply to these laws
Tech giants are in an AI arms race, but now that EU Regulators assume tech giants will either employ more content reviewers or apply automatic filtering algorithms to block some uploads, tech giants will have even more justifications to increase their AI firepower. It doesn't matter whether the justifications are legitimate or not, or to whom they are justifying it, it will probably be generic justification given to new hires, given to the American law makers, anyone really. It's harder to convince anyone that you want AI because you want power and leverage, it's easier if you say that you need AI to automatically remove hate speech, or to automatically block illegal upload of Hollywood movies. As a result, we now have one more reason why to expect AI development to progress even faster. That's scary, but that's not the actual topic of this post.
Like GDPR, these new rules will make the internet status quo overall suck more. If you access the web from Europe, you know that Cookie banners make the user experience worse, even though they are well intended regulations for your privacy. You also know that GDPR forced many companies to add privacy popups that require your interaction, and it makes the experience worse, even though the regulation was well intended. Don't get me wrong, I'm definitely a privacy-aware internet user that blocks many ads and cookies, but I'm trying to highlight the decrease of user experience as a result of new regulation.
Actual precious content is already hidden behind layers of annoyance: YouTube ads, irrelevant notifications, overall things that beg for your attention. Regulation will add more of that, which tech giants will have to comply just as a formality. They have done a great job at making user experience frictionless, but in cases of regulation that require explicit user consent before meaningful interaction, well, there is no escape.
The warnings that internet-born activists are placing are legitimate: the user experience – and freedom – on these platforms will become worse, for all of us. But what if that's just the thing we need for starting over? Is this a reboot? What if we just allowed the old internet to die away, and built something else that learns from all that we have seen so far?
I've looked at the new regulation proposal PDF, and it repeatedly talks about "uploads" to "online service providers". These are terms that were tailored to target platforms like YouTube and Facebook. They can't mention any specific company, but they choose terms that describe those platforms, such as "Online content sharing service providers perform an act of communication to the public".
Their definitions mean it applies to organizations that provide services, and have some exemptions to non-profit organizations. So they are mostly talking about for-profit companies. Further, the services are defined to be "communication to the public" and have upload as a service.
Peer-to-peer protocols seem far from that definition. For instance, Scuttlebutt is a network of friends, there is no service provider (note, in some decentralized software like Mastodon, instances/servers are actually service providers) because friends connect directly to each other. The closest thing to a service provider in Scuttlebutt would be the pub servers, which are like mirrors for a couple of feeds. These easily qualify as "providers of cloud services for individual use" which are exempt in the regulation proposal. Even if regulation would apply for those servers, I wouldn't worry about Scuttlebutt's freedom to upload/download, because I'm currently working on two new developments to peer-to-peer replication in Scuttlebutt: through distributed hash tables on the internet (like BitTorrent and Dat use), and through Bluetooth for occassions where you meet in person. Scuttlebutt is the example I'm most familiar with and can speak about, but similar networks of friends like cjdns and cwtch.im share the same kind of properties.
To summarize, once you exit the legal framework of companies providing services to the public and enter a world of friends exchanging data in private, there's little to worry about. Not only does regulation not apply, even if it would apply, it would be very hard to enforce, either through law enforcement or automatically with upload filters.
Right now, these kinds of peer-to-peer protocols are early and poorly compare to the impressive stack that tech giants have built for more than a decade. It's like rescue boats compared to the Titanic. But when Titanic is sinking, the rescue boat begins to look compelling. And when I think about an internet experience that violates my privacy, profits behind my back, silences my voice, steals my attention for ads, and forces me to read and accept regulation banners, I don't think that's a good enough sales pitch. A clean slate with just friends and 100% actual content, even with its quirky and incomplete features, begins to look very interesting. In fact, it reminds me of the early internet experience I had in 1997 which got me hooked and invited me to take part in building.
If you found this useful, you can support my writing on Patreon.